When done right, dual-write integration transforms how project-driven organizations manage everything from resource planning to financial close, unifying the front‑office ...
Learn more



Dynamics 365 Finance and Supply Chain Management Solution Architect
Ignas Stočkus is a devoted Microsoft Dynamics AX professional with more than 7 years of experience in AX2009, AX2012, and Dynamics 365 F&SCM development. Besides being responsible for new product and services development for partners and released market strategies, his responsibilities include solution technical design preparation, implementation, testing, and support duties. Skilled in X++ development for Sales, Purchases, Procurement, Logistics, Inventory and Warehouse management, Finances modules, as well as in building custom service-based integrations. In the last few years, Ignas has added one more competency next to his development projects and started a carrier as an instructor. Up to this date, Ignas has delivered a significant number of deep hands-on workshops on Dynamics AX Development Introduction, Advanced Development including SSRS reporting and standard frameworks, and Extensibility workshops on Dynamics 365 F&SCM. More than 100 Dynamics AX/Dynamics 365 F&SCM developers and programmers evaluated these workshops with the highest ranks. These workshops were conducted for both Microsoft partners and customer technical people located in Sweden, Denmark, the United Kingdom, Lithuania, Romania, Poland, Latvia, and the Czech Republic.
Ignas Stočkus is a devoted Microsoft Dynamics AX professional with more than 7 years of experience in AX2009, AX2012, and Dynamics 365 F&SCM development. Besides being responsible for new product and services development for partners and released market strategies, his responsibilities include solution technical design preparation, implementation, testing, and support duties. Skilled in X++ development for Sales, Purchases, Procurement, Logistics, Inventory and Warehouse management, Finances modules, as well as in building custom service-based integrations. In the last few years, Ignas has added one more competency next to his development projects and started a carrier as an instructor. Up to this date, Ignas has delivered a significant number of deep hands-on workshops on Dynamics AX Development Introduction, Advanced Development including SSRS reporting and standard frameworks, and Extensibility workshops on Dynamics 365 F&SCM. More than 100 Dynamics AX/Dynamics 365 F&SCM developers and programmers evaluated these workshops with the highest ranks. These workshops were conducted for both Microsoft partners and customer technical people located in Sweden, Denmark, the United Kingdom, Lithuania, Romania, Poland, Latvia, and the Czech Republic.
Latest posts by Ignas Stockus (see all)
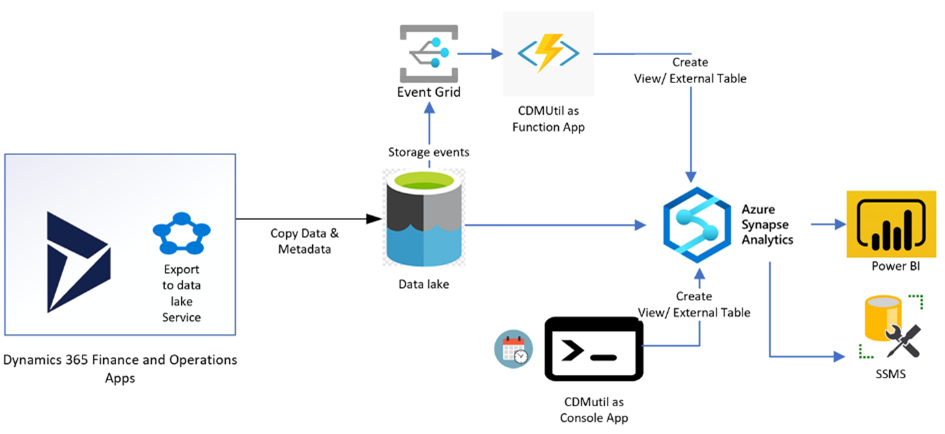
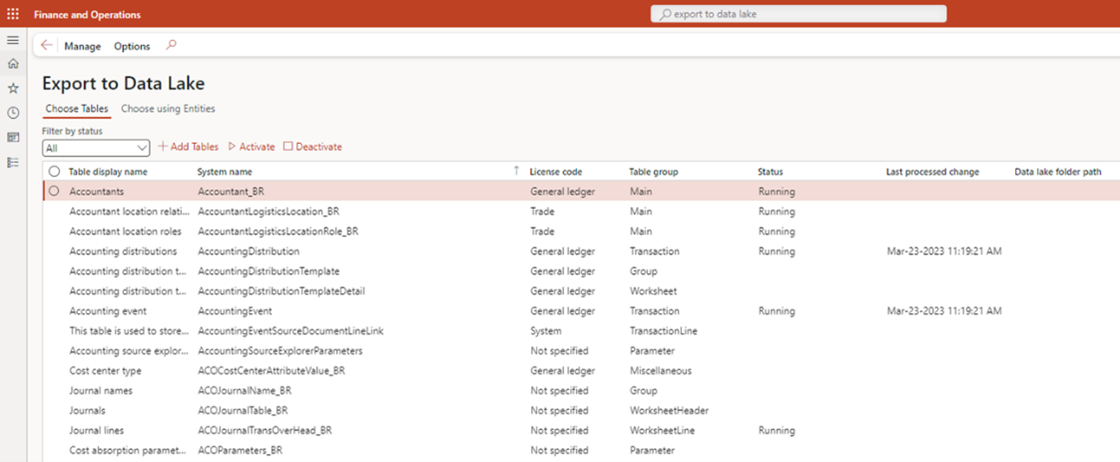
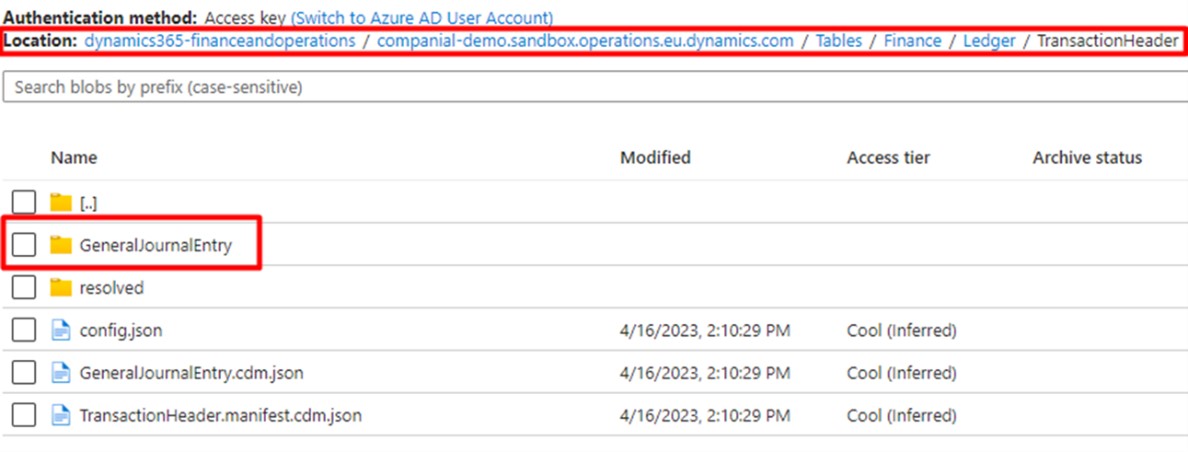
- Running Dynamics 365 Finance & Supply Chain Management Data Export with Azure Data Lake V2 and Azure Synapse: Real-Life User Story - 08/08/2023
- Running Dynamics 365 Finance & Supply Chain Management Data Export with Azure Data Lake V2 and Azure Synapse: Real-Life User Story - 29/03/2023
- How to keep the newest Dynamics 365 Finance and Supply Chain Management system updated without any hassle - 16/01/2023
A Global Partnership for Scalable Delivery
How to ensure both consistency and adaptability across the organization, empowering each entity to tailor delivery terms as needed..
Learn moreWalkerscott
“In my view, the working relationship between Walkerscott and Companial in the migration project has become strong and positive. Even ...
Learn moreAnaxco
Navigating the Dynamics 365 Transition: Anaxco's Journey to Operational Excellence with Companial's Support
Learn moreWhat’s New in the 2023 Platform Updates for Microsoft Dynamics 365 Finance & Supply Chain Management: Release wave 2
In this blog post, we’ll dive deeper into the 2023 release wave 2 for Dynamics 365 Finance and Supply Chain ...
Learn moreWhat’s New in the 2023 Platform Updates for Microsoft Dynamics 365 Finance & Supply Chain Management: Part 2
In this blog, we’ll provide you with a comprehensive overview of the upcoming and recently released improvements in Dynamics 365 ...
Learn more